We asked, you answered: Should Google add noindex support to robots.txt? Poll results
In September, I put up a poll here on Search Engine Land to see if readers would like to have an instruction in robots.txt to mark pages for No Indexation. Today I’ll present the results along with a review of what the key issues are (and why Google won’t be adding support for this).
Why would this be of interest?
In the current environment, robots.txt is used exclusively for guiding the behavior of web crawling. Further, the current approach to marking a page “NoIndex” is to place a tag on the page itself. Unfortunately, if you block it in robots.txt, Google will never see the tag and could still potentially index the page even though you don’t want that to happen.
On large sites, this presents some challenges when you have different classes of pages that you’d like to both block from crawling AND keep out of the Google index. One way that this can happen is in complex faceted navigation implementations where you have pages that you create that have significant value for users but end up presenting way too many pages to Google. For example, I looked at one shoe retailer website and found that they have over 70,000 different pages related to “Men’s Nike shoes.” This includes a wide variety of sizes, widths, colors, and more.
In some tests that I have participated in with sites with complex faceted navigation like the example I shared above we have found this large quantity of pages to be a significant problem. For one of those tests, we worked with a client to implement most of their faceted navigation in AJAX so the presence of most of their faceted nav pages was invisible to Google but still easily accessed by users. The page count for this site went from 200M pages to 200K pages – a thousand to one reduction. Over the next year, the traffic to the site tripled – an amazingly good result. However, traffic went DOWN initially, and it took about 4 months to get back to prior levels and then it climbed from there.
In another scenario, I saw a site implement a new e-commerce platform and their page count soared from around 5,000 pages to more than 1M. Their traffic plummeted and we were brought in to help them recover. The fix? To bring the indexable page count back down again to where it was before. Unfortunately, since this was done with tools like NoIndex and Canonical tags the speed of recovery was largely impacted by the time it took Google to revisit a significant number of pages on the site.
In both cases, results for the companies involved were driven by Google’s crawl budget and the time it took to get through enough crawling to fully understand the new structure of the site. Having an instruction in Robots.txt would rapidly speed these types of processes up.
What are the downsides of this idea?
I had the opportunity to discuss this with Patrick Stox, Product advisor & brand ambassador for Ahrefs, and his quick take was: “I just don’t think it will happen within robots.txt at least, maybe within another system like GSC. Google was clear they want robots.txt for crawl control only. The biggest downside will probably be all the people who accidentally take their entire site out of the index.”
And of course, this issue of the entire site (or key parts of a site) being taken out of the index is the big problem with it. Across the entire scope of the web, we don’t have to question whether this will happen or not — it WILL. Sadly, it’s likely to happen with some important sites, and unfortunately, it will probably happen a lot.
In my experience across 20 years of SEO, I’ve found that a misunderstanding of how to use various SEO tags is rampant. For example, back in the day when Google Authorship was a thing and we had rel=author tags, I did a study of how well sites implemented them and found that 72% of sites had used the tags incorrectly. That included some really well-known sites in our industry!
In my discussion with Stox, he further noted: “Thinking of more downsides, they have to figure out how to treat it when a robots.txt file isn’t available temporarily. Do they suddenly start indexing pages that were marked noindex before?”
I did also reach out to Google for comment, and I was pointed to their blog post when they dropped support for noindex in robots.txt back in 2014. Here is what the post said about the matter:
“While open-sourcing our parser library, we analyzed the usage of robots.txt rules. In particular, we focused on rules unsupported by the internet draft, such as crawl-delay, nofollow, and noindex. Since these rules were never documented by Google, naturally, their usage in relation to Googlebot is very low. Digging further, we saw their usage was contradicted by other rules in all but 0.001% of all robots.txt files on the internet. These mistakes hurt websites’ presence in Google’s search results in ways we don’t think webmasters intended.“
* Bolding of the last sentence by me was done for emphasis.
I think that this is the driving factor here. Google acts to protect the quality of its index and what may seem like a good idea can have many unintended consequences. Personally, I’d love to have the ability to mark pages for both NoCrawl and NoIndex in a clear and easy way, but the truth of the matter is that I don’t think that it’s going to happen.
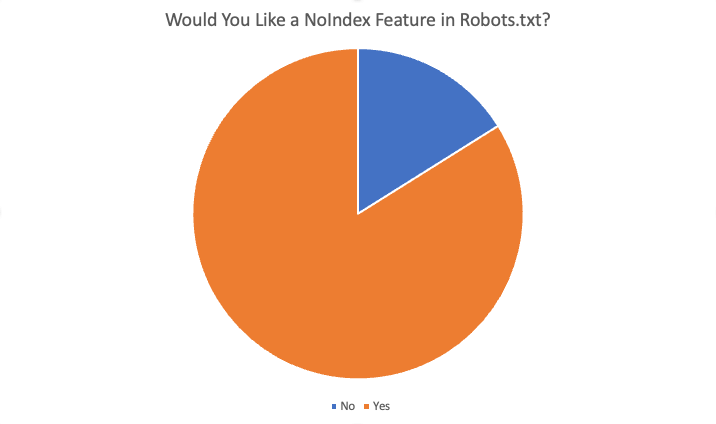
Overall robots.txt poll results
First, I’d like to acknowledge a flaw in the survey in that question 2, a required question, assumed that you answered question 1 with a “yes”. Thankfully, most people who did answer “no” on question 1 clicked on “Other” for question 2 and then entered in a reason for why they didn’t want this capability. One of those responses noted this flaw and said, “Your poll is misleading.” My apologies for the flaw there.
The overall results were as follows:
In total 84% of the 87 respondents said “yes,” they would like this feature. Some of the reasons offered for wanting this feature were:
- There are no situations where I want to block crawling but have pages indexed.
- Noindexing a large number of pages takes a lot of time because Google has to crawl the page to see the noindex. When we had the noindex directive we could achieve quicker results for clients with over-indexation problems.
- We have a very large cruft problem…very old content…hundreds of old directories and sub-directories and it takes seemingly months if not years to de-index these once we delete and ergo 404 them. Seems like we could just add the NoIndex rule in the robots.txt file and believe that Google would adhere to this instruction much quicker than having to crawl all the old URLs over time …and repeatedly…to find repeating 404’s to finally delete them…so, cleaning up our domain(s) is one way it would help.
- Save development effort and easily adjustable if something breaks because of changes
- Can’t use always a “noindex” and too many pages indexed that should not be indexed. The standard blocking for spider should also “noindex” the pages at least. If I want a search engine not to crawl a URL/folder, why would I want them to index these “empty” pages?
- Adding new instructions to an .txt file is much quicker than getting Dev resources
- Yes, it’s hard to change meta in head for enterprise CRM so individual noindex feature in robots.txt would solve that problem.
- Quicker, less problematic site indexing blocking 🙂
Other reasons for saying no included:
- Noindex tag is good enough
- New directives in robots.txt file are not necessary
- I don’t need it and don’t see it working
- Don’t bother
- Do not change
Summary
There you have it. Most people who responded to this poll are in favor of adding this feature. However, bear in mind that the readership for SEL consists of a highly knowledgeable audience – with far more understanding and expertise than the average webmaster. In addition, even among the yes responses received in the poll, there were some responses to question 4 (“would this feature benefit you as an SEO? If so, how”) that indicated a misunderstanding of the way the current system works.
Ultimately though, while I’d personally love to have this feature it’s highly unlikely to happen.
The post We asked, you answered: Should Google add noindex support to robots.txt? Poll results appeared first on Search Engine Land.